
在本文中,我们将回顾Apache Beam的概念,历史和未来,它们很可能成为数据处理管道定义的新标准 。
在2018年柏林的Dataworks峰会上,我参加了Apache Beam副总裁Davor Bonaci,以前从事Google Cloud Dataflow的会议,该会议使用Apache Beam进行统一,可移植和高效的数据处理的现在和将来 。 这次会议激起了我的好奇心,使我写了这篇文章,分为两部分:
- 会议中简要介绍了Apache Beam背后的概念;
- Beam本身的演示,以及项目的一些历史,当前状态和未来。
Apache Beam背后的概念
在讨论Beam本身之前,我们将探讨其实现的概念。 本简介基于Google数据处理语言和系统小组技术主管Tyler Akidau撰写的两篇文章(Streaming 101和Streaming 102)。 他是Dataflow模型论文的主要作者之一,该论文基于Apache Beam的前身Google Cloud Dataflow。
流媒体
首先,让我们看看在谈论数据处理时流意味着什么。
一种数据处理引擎,设计时考虑了无限的数据集
— 泰勒·阿基道 ( Tyler Akidau)
流的特点是:
- 无界数据集(与有限数据集相反);
- 无限数据处理(及时);
- 低延迟,近似和/或推测性结果。
由于它们的近似结果 ,通常将流系统与功能更强大的批处理系统结合使用,以提供正确的结果。 Lambda体系结构就是这种想法的一个很好的例子。 它由两个系统组成:
- 流系统 ,提供低延迟,不准确的结果;
- 稍后提供正确结果的批处理系统 。
Lambda体系结构运行良好,但引入了维护问题:您必须构建,设置和维护数据管道的 两个版本 ,然后合并结果。
为了降低架构的复杂性,Jay Kreps合并了流传输层和批处理层以定义Kappa Architecture 。 该架构由应用连续数据转换的单个管道组成,并使用能够同时传输和存储数据的数据存储(例如Apache Kafka)。
泰勒·阿基道(Tyler Akidau)通过质疑当今对批处理系统的需求,使事情更进一步。 对他而言,流系统仅需克服两件事:
- 正确性 ,这是由精确的一次处理带来的,因此具有一致的分区容忍性存储 (以确保已处理了哪些数据);
- 时间推理工具 ,用于处理事件时间偏斜不同的无边界,无序数据。
新数据将到达,旧数据可能会被收回或更新,我们构建的任何系统都应能够独自应对这些事实,完整性的概念是一种方便的优化方法,而不是语义上的必要性。
— 泰勒·阿基道 ( Tyler Akidau)
泰勒·阿基道(Tyler Akidau)的团队为这种数据处理定义了一个模型,该模型基于Google Cloud Dataflow以及Apache Beam: Dataflow模型 。
词汇
要了解数据流模型,我们必须引入一些关键字。
活动时间与处理时间
处理数据时,需要注意的两个时间范围是:
- 事件时间 ,实际发生事件的时间;
- 处理时间 ,系统中观察到事件的时间。
在现实生活中,事件时间与处理时间之间的时滞是高度可变的(由于硬件资源,软件逻辑和数据本身的发出):
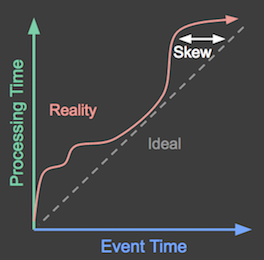
图1:事件时间与处理时间之间的差异
视窗
要处理无限制的数据集,有必要将其分成有限的部分。 这些有限的数据块称为窗口 。 窗口由长度和句点定义:
- 固定窗口:固定长度和周期相等;
- 滑动窗口:长度和周期固定,但周期可以小于长度(导致重叠);
- 会话:长度和周期都不固定。 窗口是由不活动间隙分隔的事件序列定义的。

图2:3种窗口类型
在定义窗口的时间边界时,我们有两个选择:
- 像许多现有系统一样,依赖处理时间,但是某些数据最终将在错误的处理窗口中显示(由于事件时间和处理时间之间存在偏差)。
- 依靠事件时间,但这实际上是不可能的,因为您不知道已经观察到了时间窗口内发生的所有数据。
水印
水印使用以下语句将事件时间E链接到处理时间P:“在时间P,已观察到在E之前生成的所有数据”。 水印取决于数据源,我们根据数据知识对其进行设置。 使用Apache Beam,水印的计算由系统完成,并在处理数据时进行完善。
触发
触发器定义何时应为窗口实现输出。 如果我们设置多个触发器,那么最终会得到多个结果。 如果这些结果是在观察所有数据之前计算的,则可能是推测性的。
数据流模型
数据流模型允许通过回答4个问题来定义数据管道:
- 计算出什么结果?
- 结果在哪里计算?
- 在处理时间何时实现?
- 细化结果如何关联?
为了更好地理解如何将这些问题应用于实际的用例,我将使用Apache Beam网站上提供的一个很好的GIFS示例示例。 泰勒·阿基道(Tyler Akidau)在他的文章Streaming 102中提供了一个更复杂的示例,他将其链接到Google Cloud Dataflow SDK。
计算出什么结果?
换句话说:哪些转换应用于数据?
假设我们收到了来自不同玩家的分数,并且我们希望对每个用户在一天内得出的分数求和。 这对应于一个单一的转换: 按键求和 (一个键对应一个用户)。 如果我们每天处理一次数据,它将为我们提供以下信息:
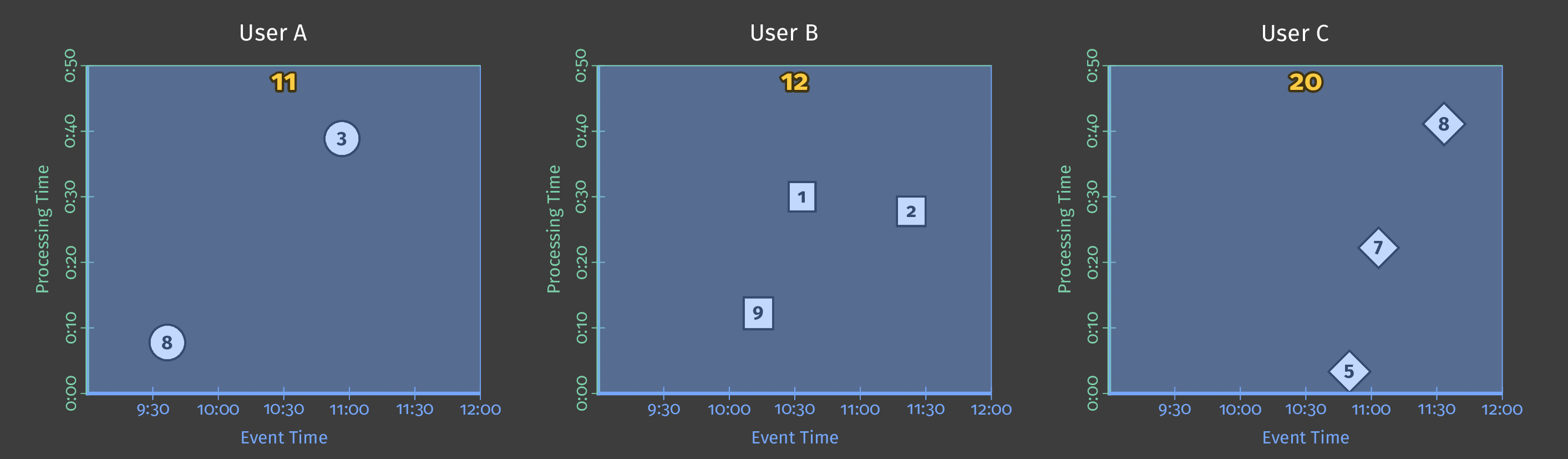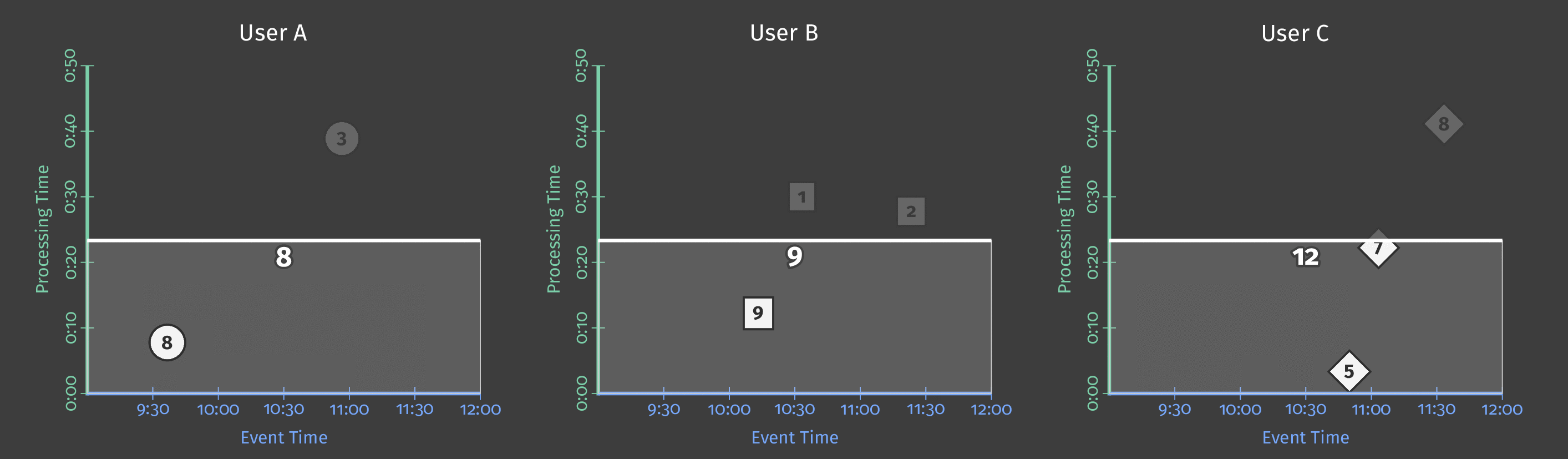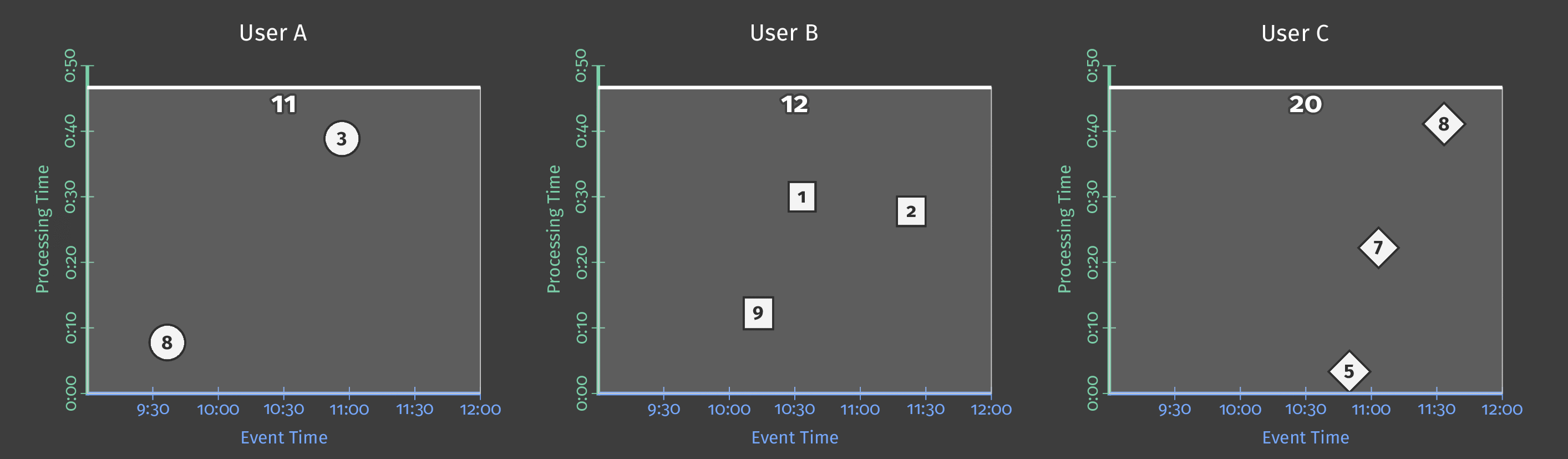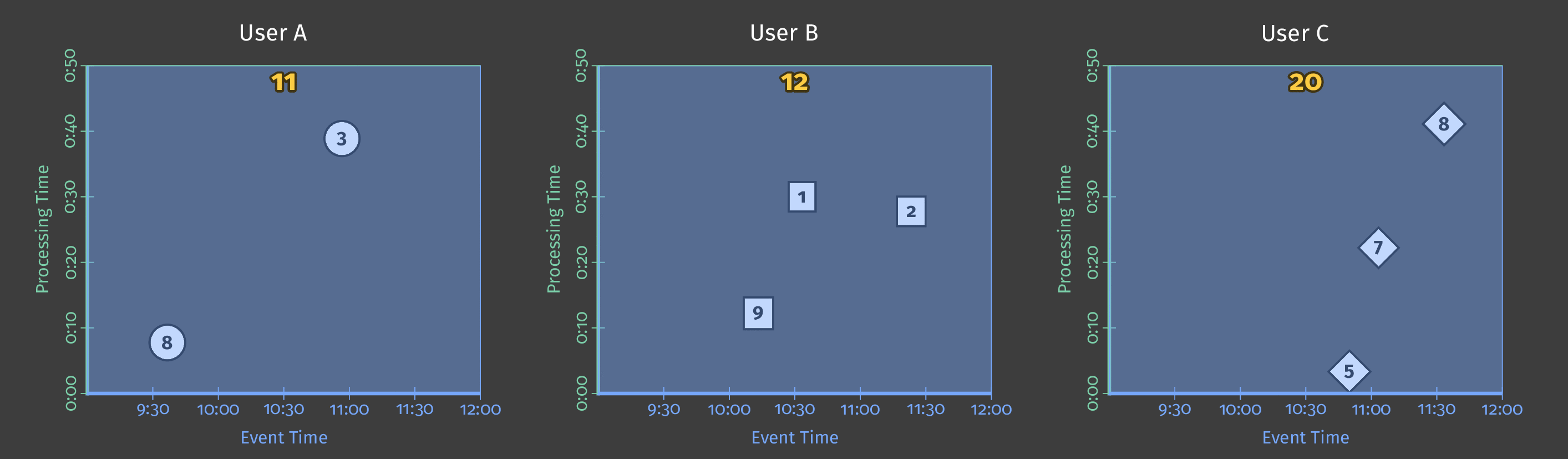
图3:用户的分数总和
在此动画(以及本文中的所有下一个动画)中,接收到的数据由圆圈,正方形和菱形表示,白线表示处理时间的进度,并且在实现时结果变为黄色。
在这里,我们一次处理所有数据并获得单个结果,这相当于经典的批处理。
结果在哪里计算?
换句话说:哪些窗口用于拆分数据?
假设我们现在想要每个用户每小时的分数总和。 为此,我们在事件时间中定义了一个固定的1小时窗口,每个窗口都会给我们一个总分:
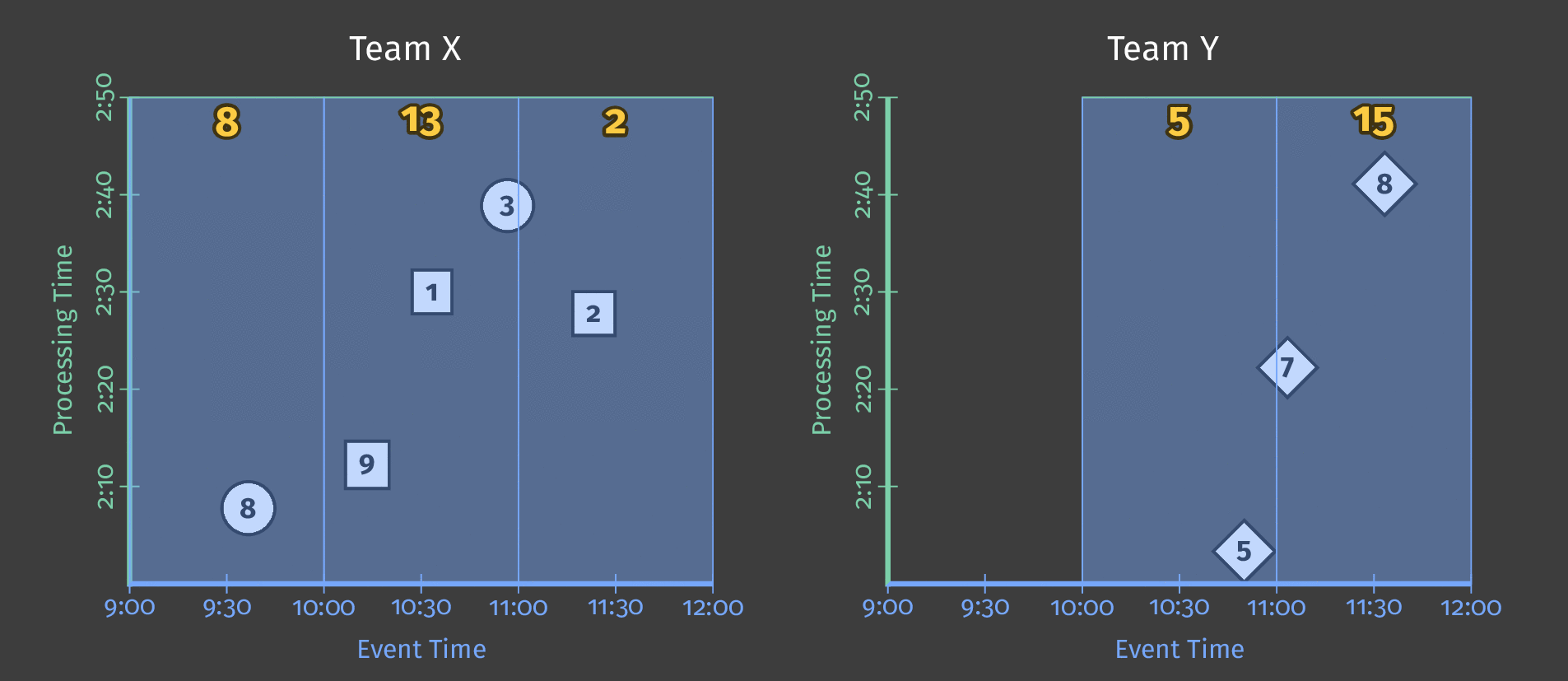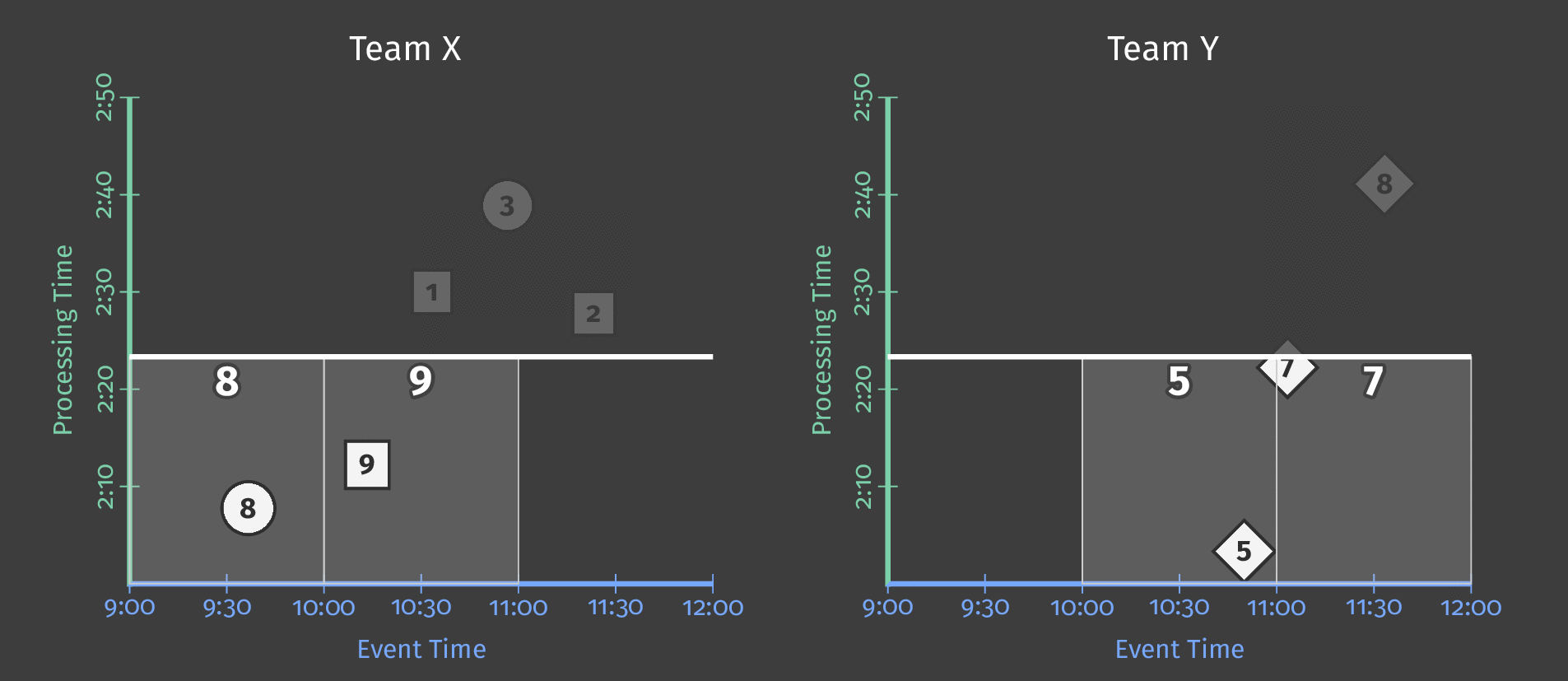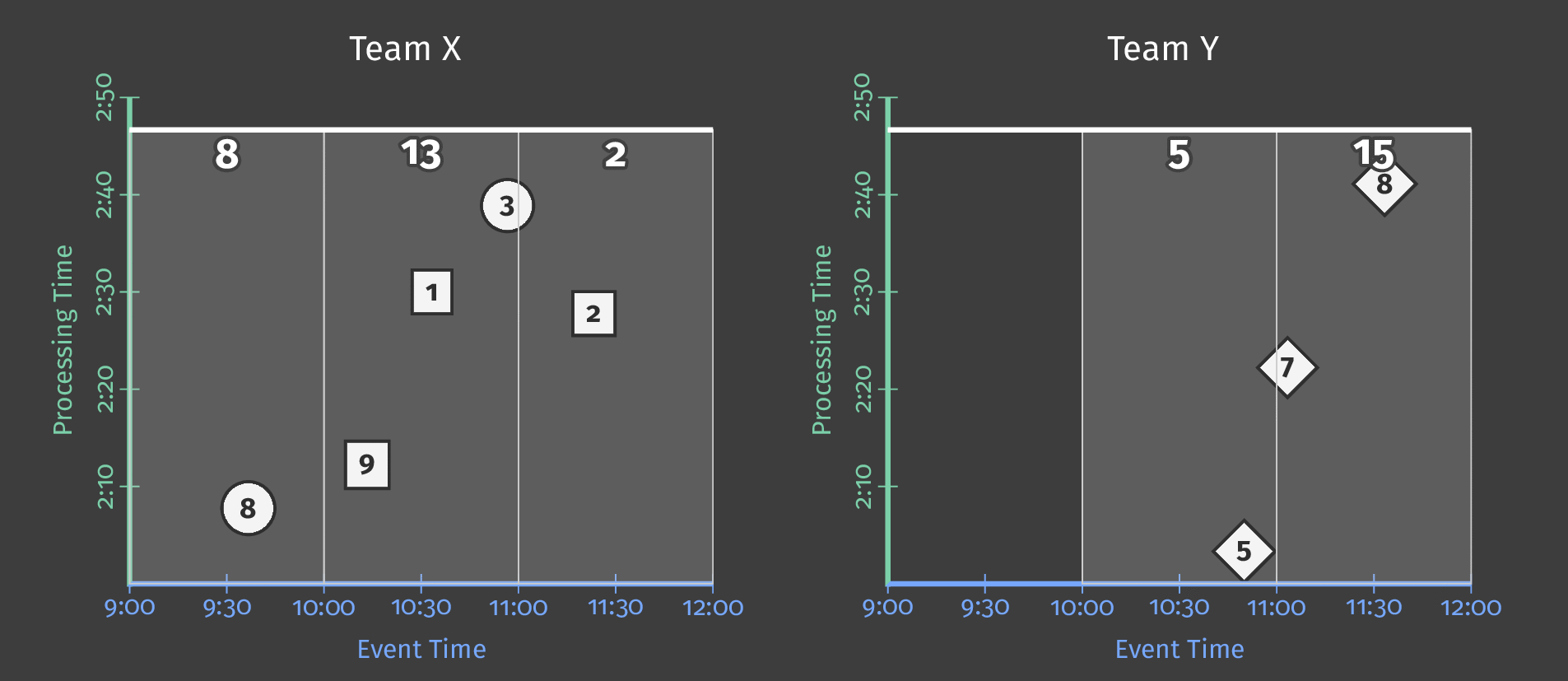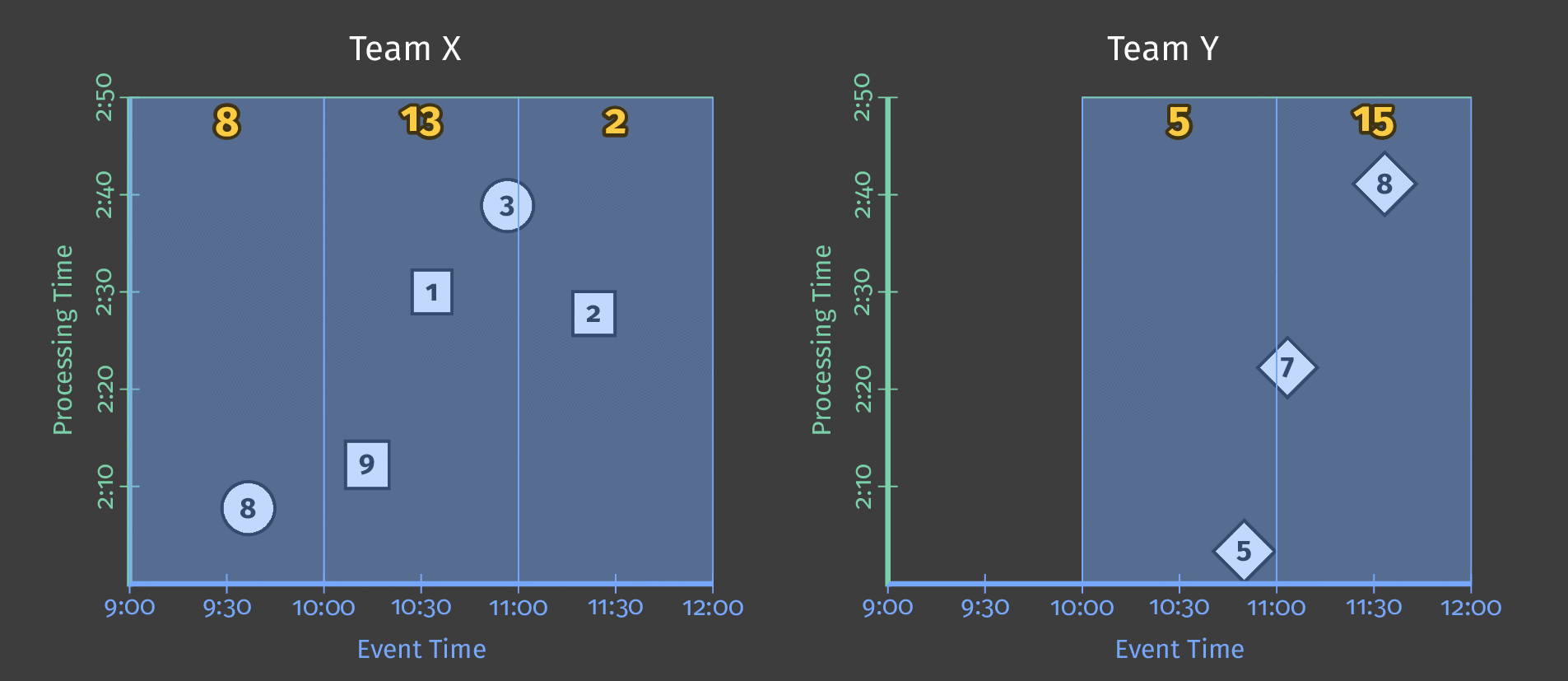
图4:每小时的用户分数总和
我们仍处于批处理流程中,因为我们在实现结果之前等待所有结果,但是我们得到3个独立的结果。
在处理时间何时实现?
换句话说:关于什么触发因素将实现?
如果要从批处理流水线切换到蒸腾的流水线,我们将面临前面解决的问题:我们无法确定是否已观察到窗口的所有数据。
这就是为什么我们将使用可以基于以下条件的触发器的原因:
- 水印进度 ,提供可能是窗口最终结果的结果(当水印与窗口的末端匹配时);
- 处理时间进度 ,以提供定期的定期结果(例如,每10分钟);
- 元素计数 ,在观察到N个新元素(例如,每5个元素)后提供结果;
- 标点符号 ,当在记录中检测到特殊功能(例如EOF元素)时提供结果。
这是一个示例,如果观察到新元素,则每10分钟触发一次求和结果:
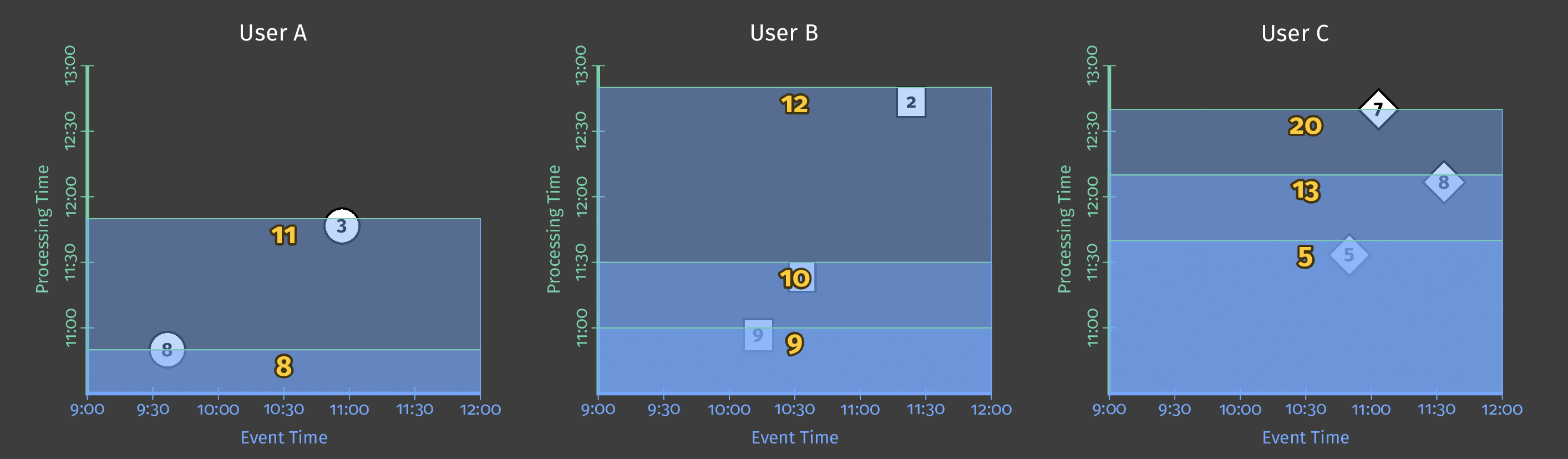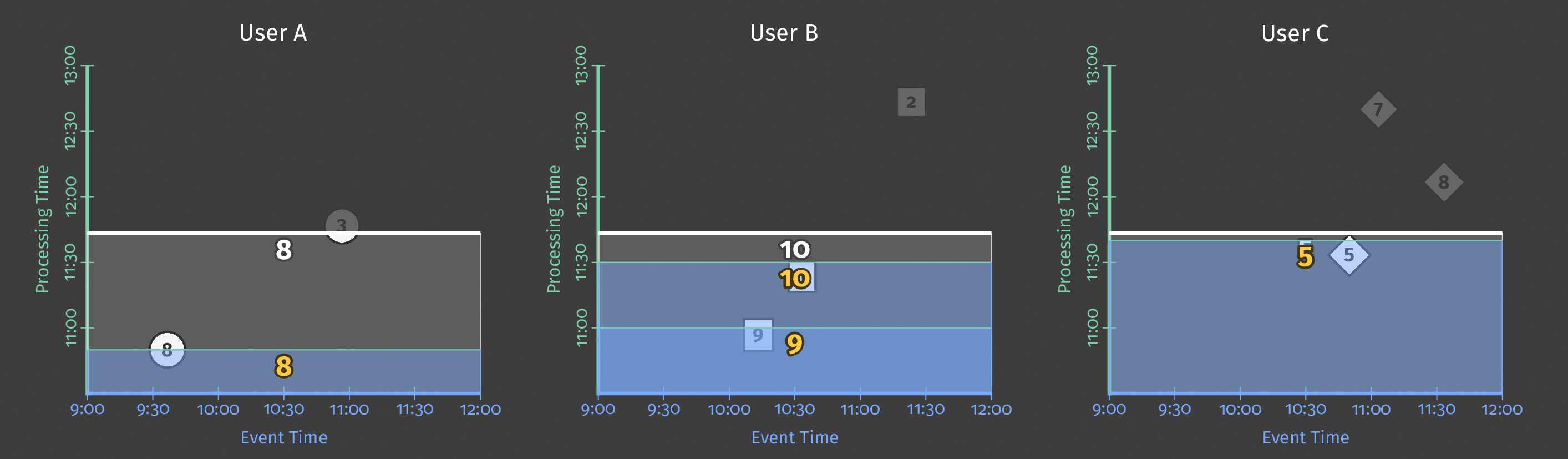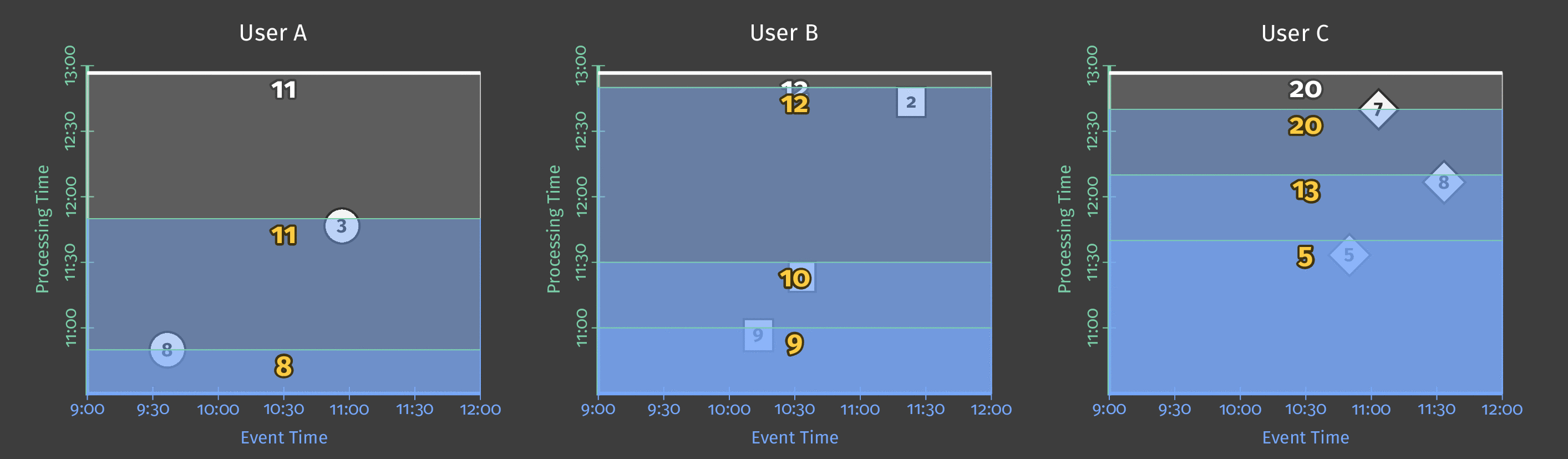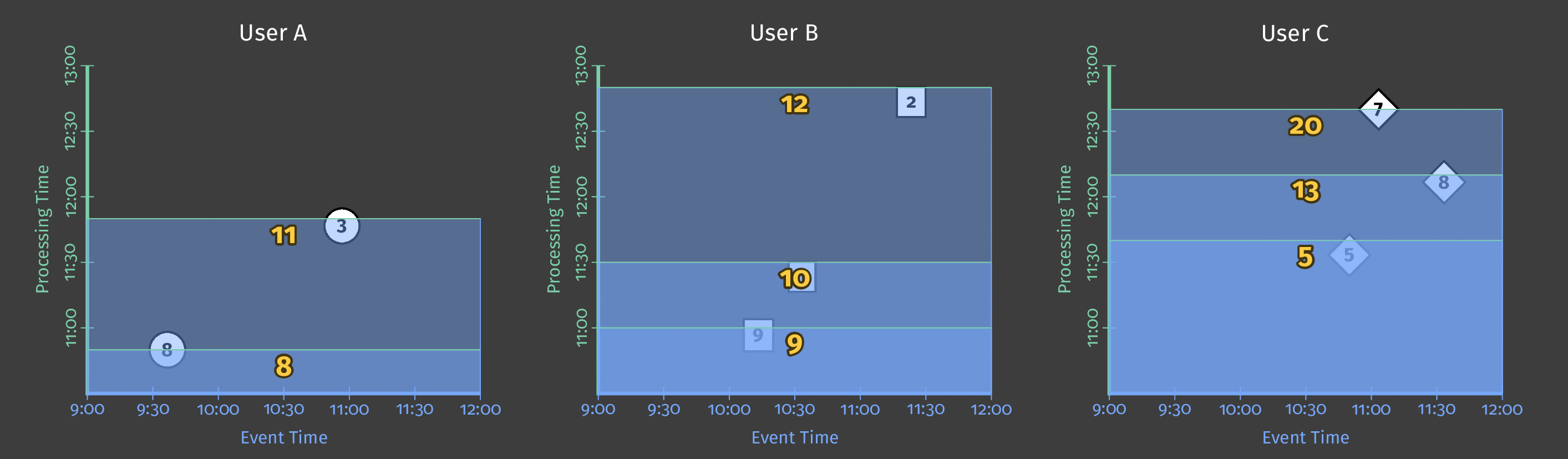
图5:如果观察到新元素,则每10分钟触发一次
我们可以在数据管道中使用多个触发器并定义复合触发器(基于重复,连接,其他触发器的序列)。
数据流模型标签针对水印分为3类:
- 在水印之前出现的早期 ;
- 在水印出现时准时 ;
- 在水印之后出现时晚 。
在下面的动画中,我们选择在观察到的每个新元素处触发结果(水印以绿色绘制)。
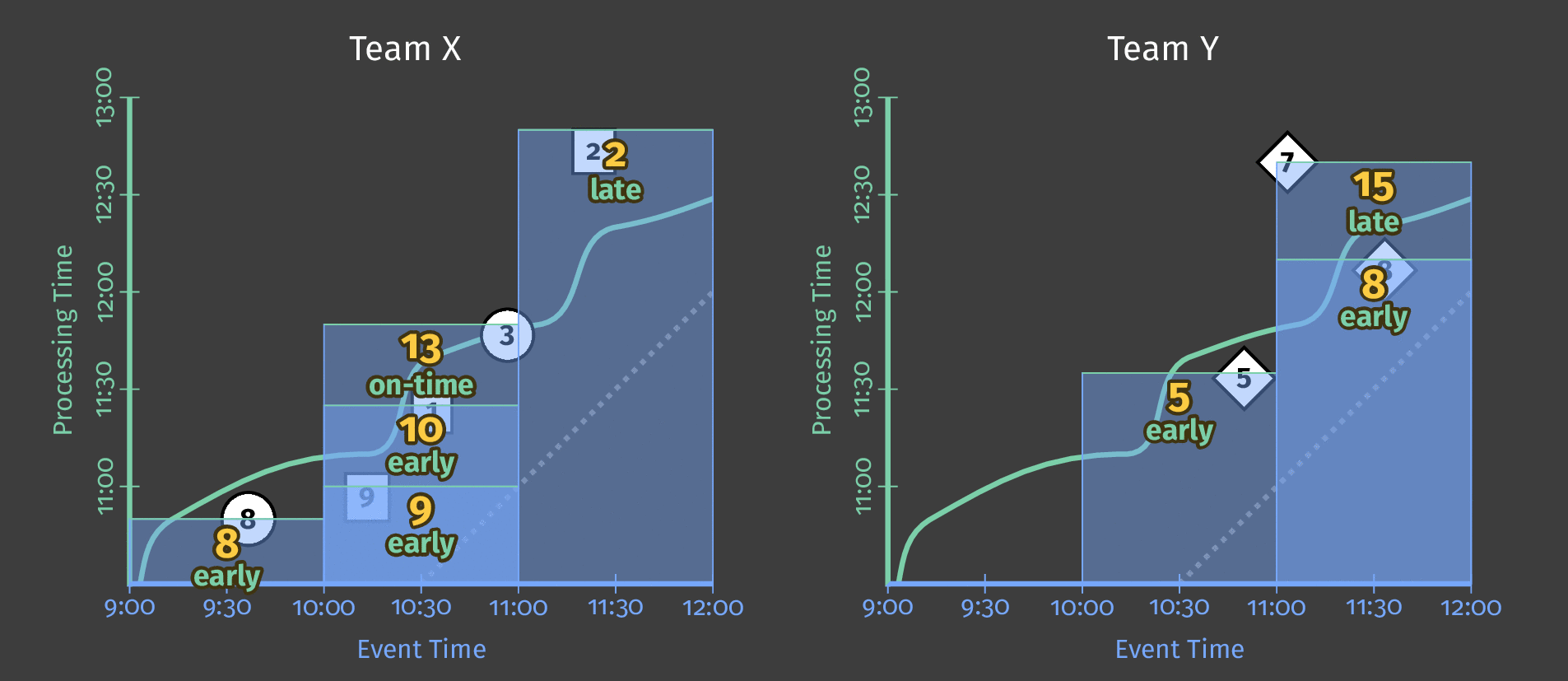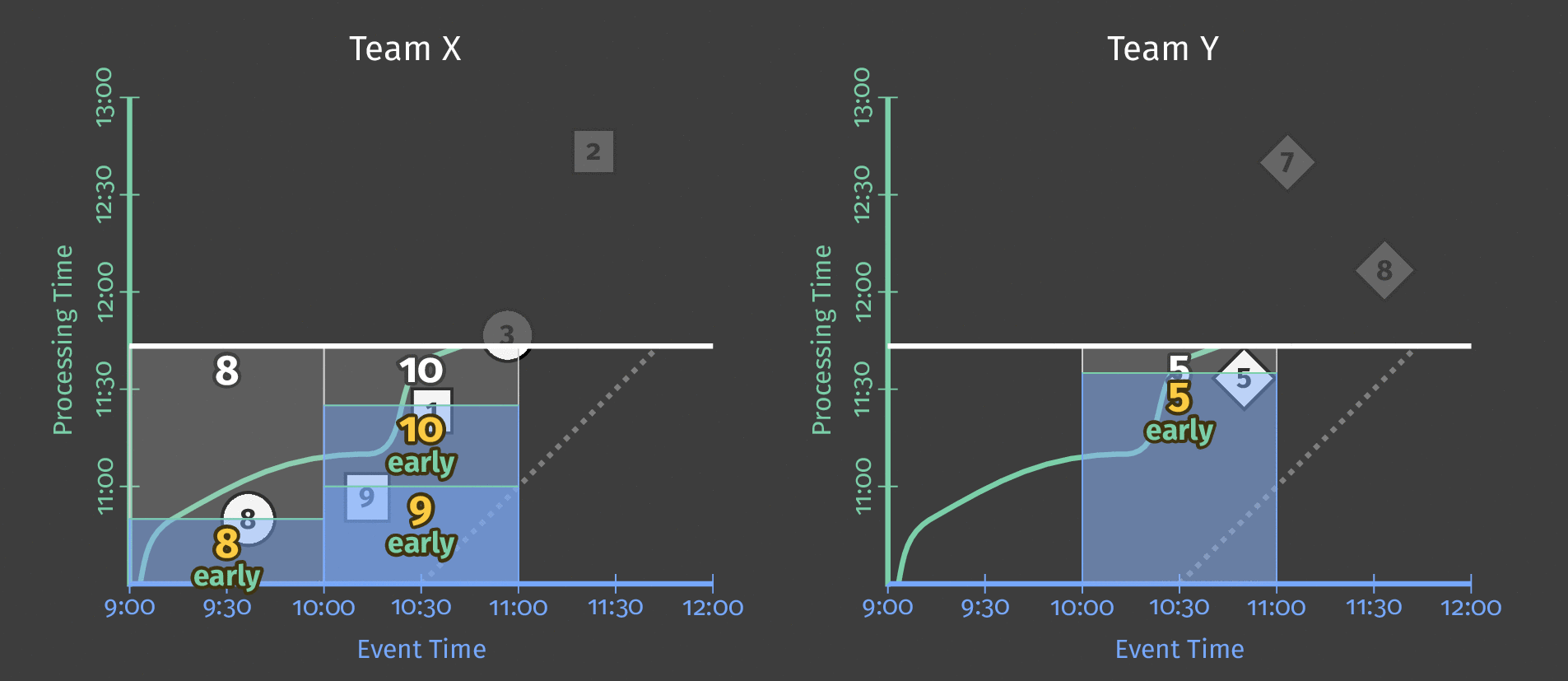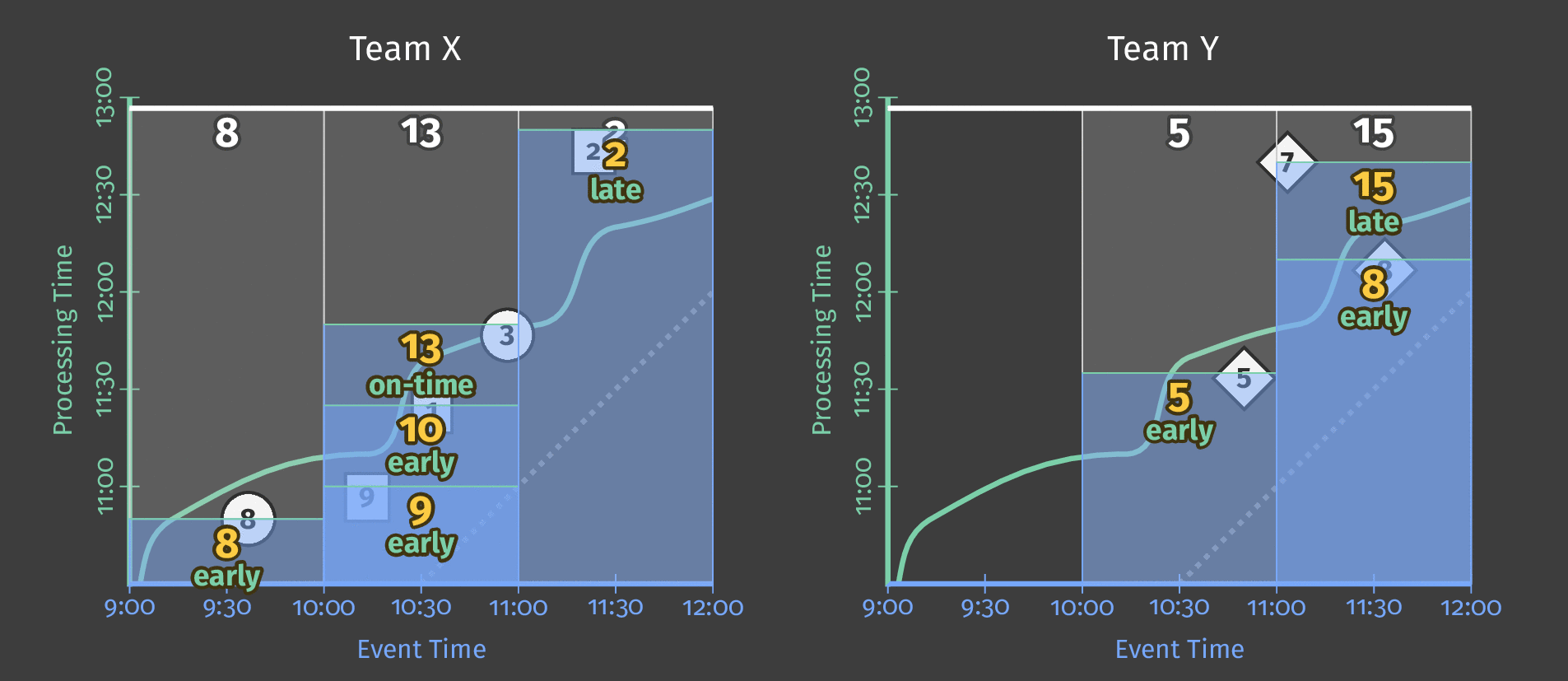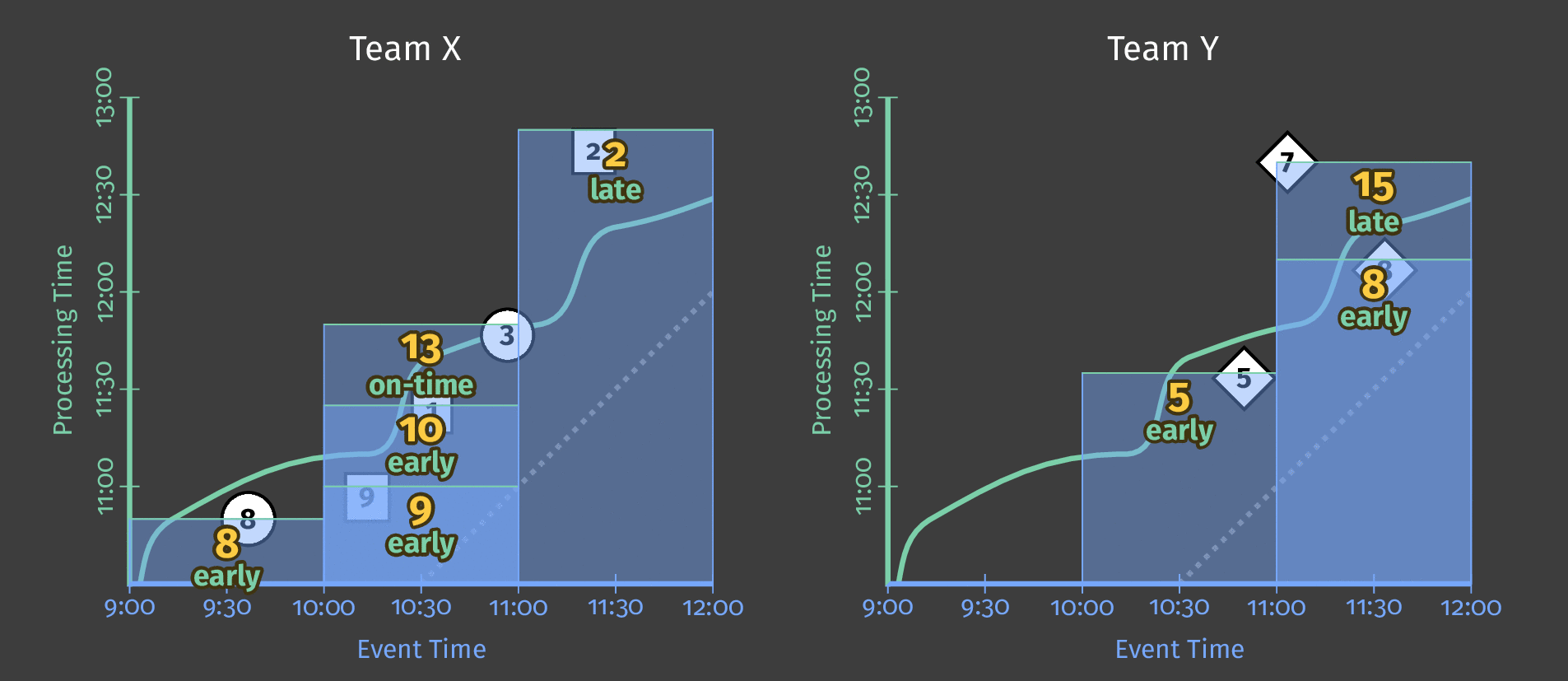
图6:触发结果与水印
细化结果如何关联?
换句话说:我们为结果选择哪种累积模式?
数据流模型为窗口的多个结果提供3种累积模式:
- 丢弃:当前结果未考虑过去的结果。 如果要对结果求和,则在消耗它们时必须手动进行。
- 累加:当前结果累加所有过去的结果。 如果是求和,则窗口的最后结果将是总和。
- 累加和丢弃:当前结果累加所有过去的结果,但对过去的结果产生独立的撤消(“我以前告诉过您结果是X,但我错了。摆脱上一次告诉您的XI并替换为Y.”)。
数据流模型就是这样! 如果Dataflow团队是正确的,则回答这4个问题应该可以描述用于批处理或流处理的每个数据管道 。 如果您想深入研究数据流模型的理论概念,我邀请您阅读Tyler Akidau的文章,这些文章写得很好(Streaming 101和Streaming 102)。
阿帕奇光束
Apache Beam的目的是提供一个可移植的标准,用于在各种平台上以多种语言表达健壮的,乱序的数据处理管道。
由Google发起并得到广泛支持
Apache Beam成立于2016年初,当时Google和其他合作伙伴(Google Cloud Dataflow的贡献者)决定将Google Cloud Dataflow SDK和运行程序移至Apache Beam孵化器。 泰勒·阿基多(Tyler Akidau)本人在“ 为什么要使用Apache Beam”一文中很好地描述了Google做出此决定的原因。
许多支持Beam模型合法性并为Apache Beam的发展做出贡献的组织都是数据处理领域的领导者,例如Talend( 文章 )或data Artisans( 文章 )。
很快,对我们来说显而易见的是,数据流模型[…]是用于流和批处理数据处理的正确模型。 […] Flink Datastream API […]忠实地实现Beam模型
— 数据工匠首席执行官兼Apache Flink创始人Kostas Tzoumas
这给Apache Beam带来了很多信誉,该产品于2017年1月10日成为Apache顶级软件基础项目。
混合搭配SDK和运行时
达沃·波纳奇(Davor Bonaci)在柏林举行的会议的近一半实际上是关于Beam的愿景的:允许开发人员轻松地基于Beam模型(= Dataflow模型)表达数据管道,并在以下各项之间进行选择:
- 多个SDK来编写管道: Java,Python(目前仅在Google Cloud Dataflow运行器上),Go(实验性)
- 多个运行程序来执行管道: Apache Apex,Apache Flink,Apache Spark,Google Cloud Dataflow,Apache Gearpump(正在孵化)
这是我们如何使用Java SDK编写图6所示的数据管道:
PCollection <KV >分数=输入
.apply(Window.into(FixedWindows.of(Duration.standardHours(1)))
。触发
AtWatermark()
.withEarlyFirings(AtCount(1))
.withLateFirings(AtCount(1)))
.accumulatingPanes())
.apply(Sum.integersPerKey());
梁的未来
鉴于主要数据处理引擎对Beam模型的强烈信心,未来几年可能会对Beam生态系统进行很多扩展(语言,运行程序以及DSL,库,数据库等)。 。 达沃·博纳奇(Davor Bonaci)强烈建议如果我们错过将其整合到环境中的作品,请为Beam做贡献。
正如我们在功能矩阵中看到的那样,某些Beam模型概念尚不适用于所有Beam运行器(尤其是对于错过了许多触发器类型的Spark)。 再次,Beam模型的接受度越来越高,应该促使不同的跑步者适应他们的框架。
Beam团队和贡献者还致力于集成新功能,例如:
- 流分析:通过使用连续查询来分析实时数据并对其执行操作;
- 复杂事件处理 :匹配流中事件的模式,以检测数据中的重要模式并对它们做出反应。 此功能将受到FlinkCPE库(JIRA)的启发。
结论
我们已经看到Apache Beam是一个旨在围绕Dataflow模型统一多个数据处理引擎和SDK的项目,它提供了一种轻松表达任何数据管道的方法。 这些特性使Beam成为一个非常雄心勃勃的项目,可以吸引数据处理的最大参与者来建立共享相同语言的新生态系统,而实际上这已经开始了。
参考文献
- 串流101 ,泰勒·阿基道,奥赖利,https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
- 流媒体102 ,泰勒·阿基道(Tyler Akidau),奥莱利(O’Reilly),https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
- 数据流模型:一种在大规模,无界,无序数据处理中平衡正确性,延迟和成本的实用方法 ,泰勒·阿基道,罗伯特·布拉德肖,克雷格·钱伯斯,斯拉瓦·切尔纳克,拉斐尔·J·费尔南德斯·莫克祖玛,鲁汶Lax,Sam McVeety,Daniel Mills,´Frances Perry,Eric Schmidt,Sam Whittle,http://www.vldb.org/pvldb/vol8/p1792-Akidau.pdf
- Apache Beam网站https://beam.apache.org/
- 2017年的Apache Beam:用例,进步和持续创新 ,让-巴蒂斯特·奥诺弗雷,塔伦德,https://www.talend.com/blog/2018/01/30/apache-beam-look-back-2017
- 为什么选择Apache Beam? ,Kostas Tzoumas,数据工匠,https://data-artisans.com/blog/why-apache-beam
图片
- 图1、2:Tyler Akidau
- 图3、4、5、6:https://beam.apache.org/get-started/mobile-gaming-example/
